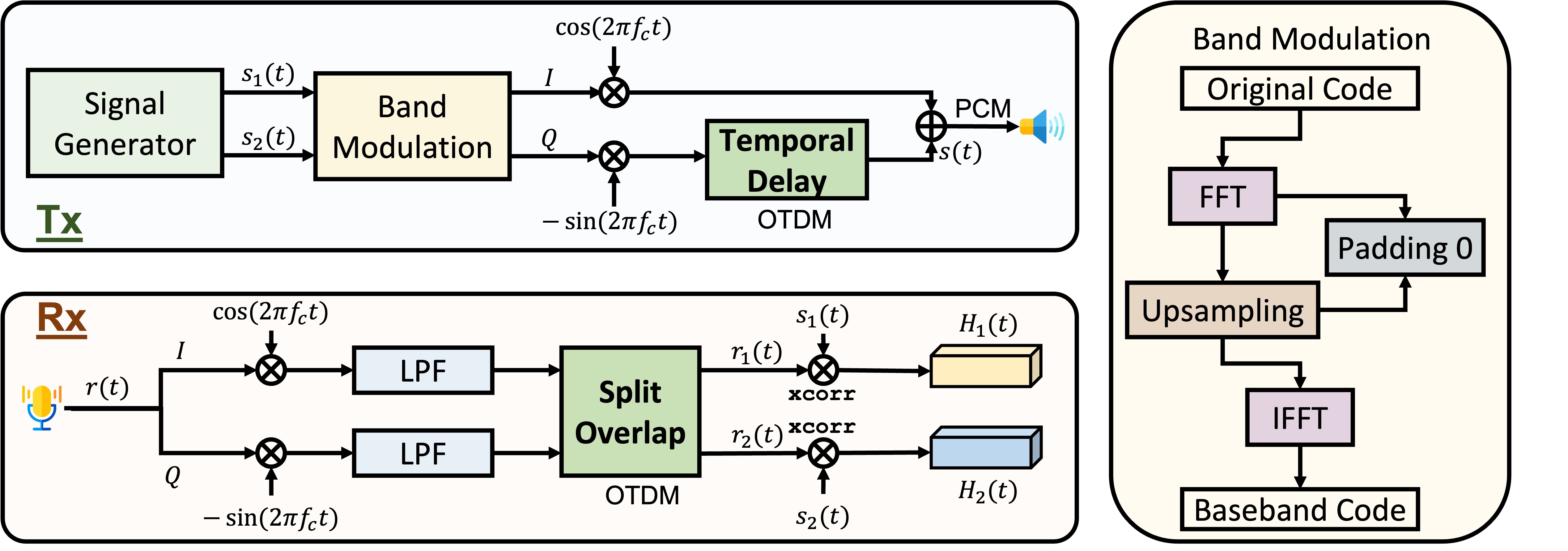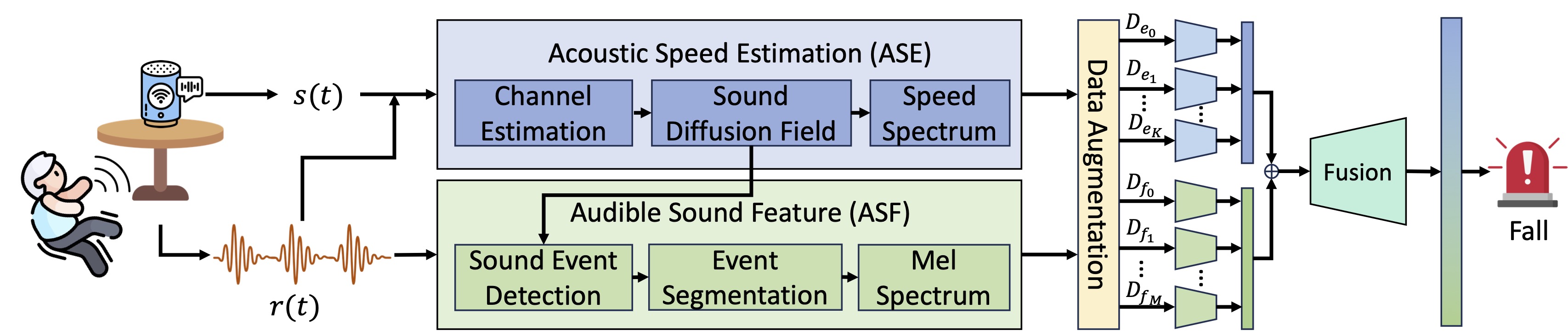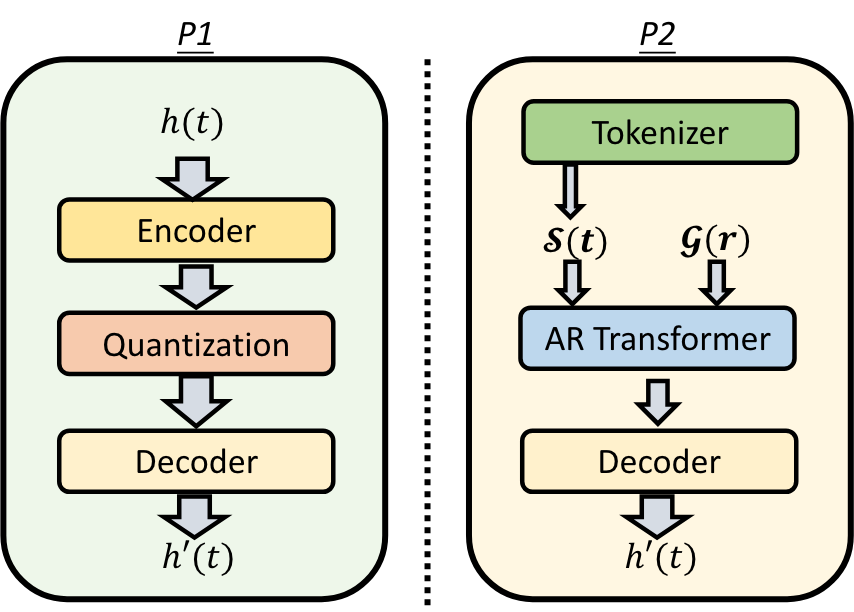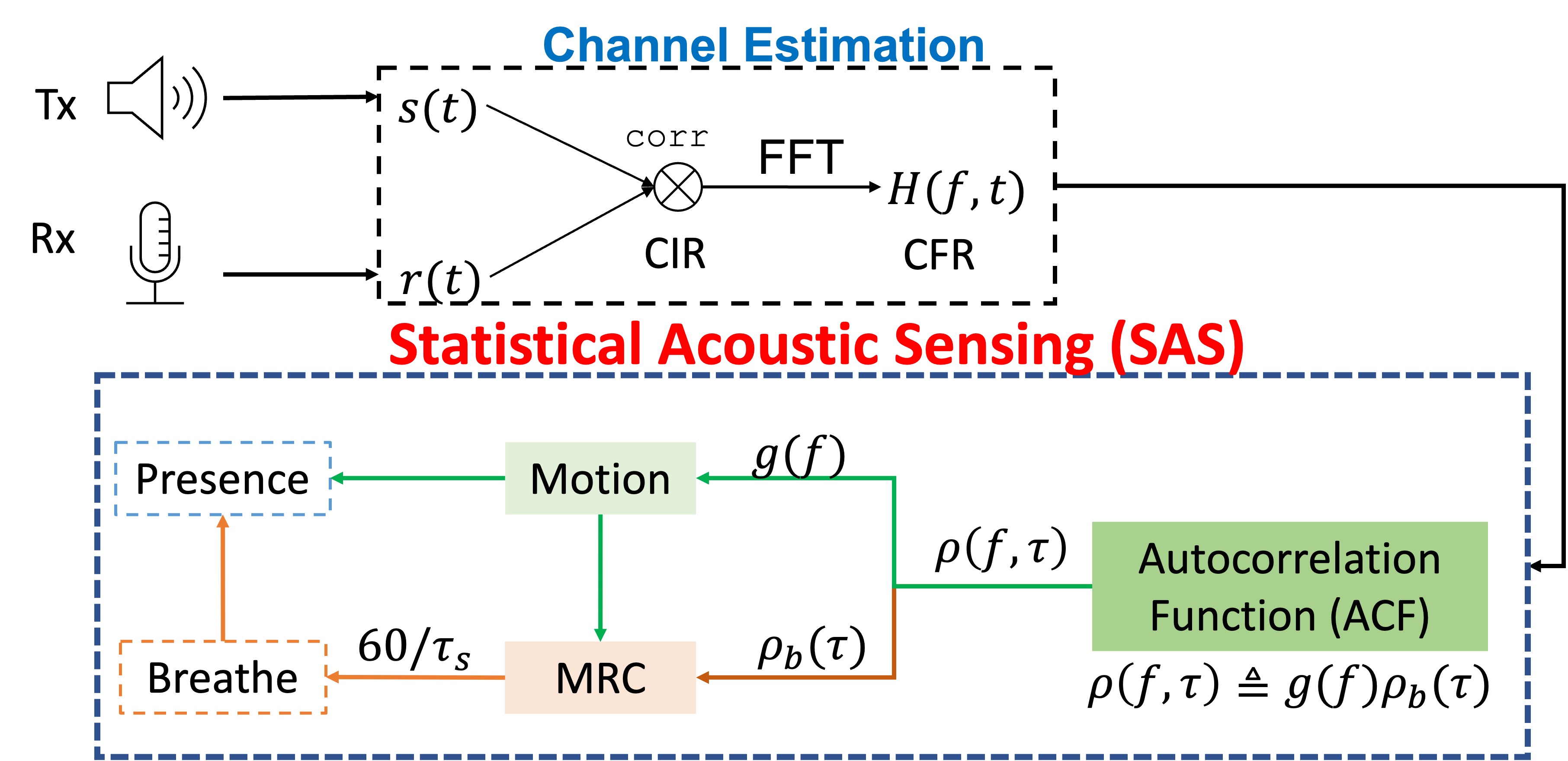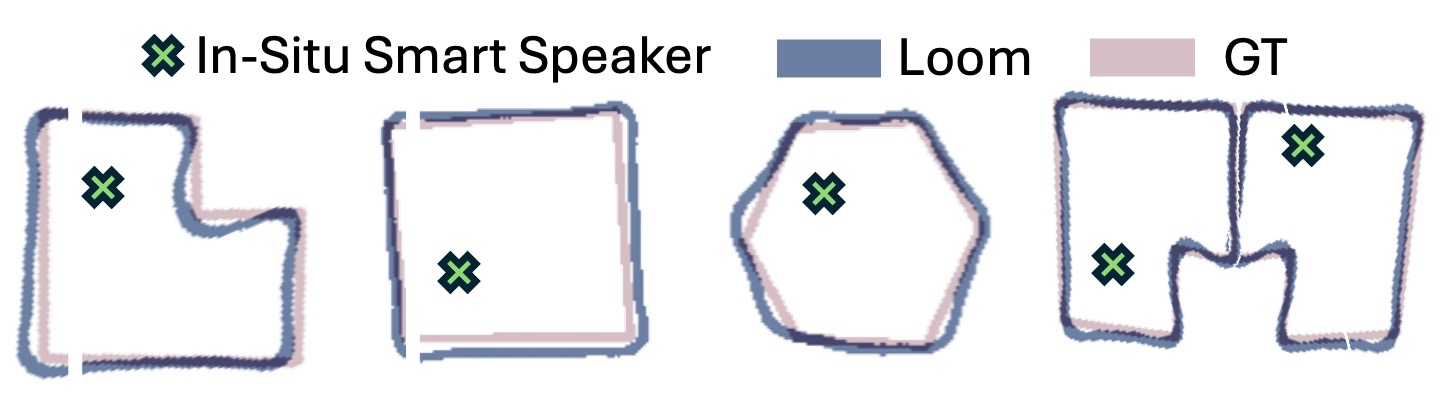
Abstract
Accurate indoor floorplans are foundational for emerging smart home applications. Yet, acquiring this geometry typically relies on intrusive dedicated hardware or active crowdsourced mobile scanning, rendering widespread adoption impractical. In this paper, we present Loom, the first neural floorplan inference system that recovers room geometry using in-situ, commodity smart speakers without any active user intervention. However, translating sparse, stationary acoustic signals into geometric boundaries is a highly ambiguous, ill-posed inverse problem. Loom breaks this physical barrier through three core innovations. First, we formulate the layout reconstruction as a physics-guided conditional generation task. At its core, we design a proxy network to model acoustic propagation and constrain the structural search space. Second, we opportunistically reuse ambient echoes from daily user-device interactions as dynamic sound sources, unlocking multi-view spatial parallax without extra burden. Third, we employ a self-evolving mechanism to seamlessly adapt to unlabeled, heterogeneous room semantics out-of-the-box. Extensive evaluations show that Loom achieves an SSIM of 0.83 in furnished rooms. We believe Loom will pave the way for the ubiquitous spatial intelligence.